Squonk job execution

Tim Dudgeon 2024-01-29
POST
We’ve not blogged about our Squonk2 products much up to now. This is the first is a series of posts that addresses this. We start with describing Jobs, a key part of Squonk Data Manager. A job is something you can execute. Something that does some work. A job can be simple, such as a Python or Java script that processes some molecules and calculates or predicts some molecular properties, or it could be a complete virtual screening workflow that runs in parallel on the cluster and could take days to complete. But in essence, a job is something that has inputs (e.g. files), has options (e.g. user define parameters for execution) and generates outputs (e.g. files).
Have a look at our guide to running jobs and guide to inspecting results in the Squonk2 documentation for an overview of how to run a job. The output can look like this, showing the inputs, outputs and options for the job, letting you see the event messages that job creates, viewing the execution log and various other things:
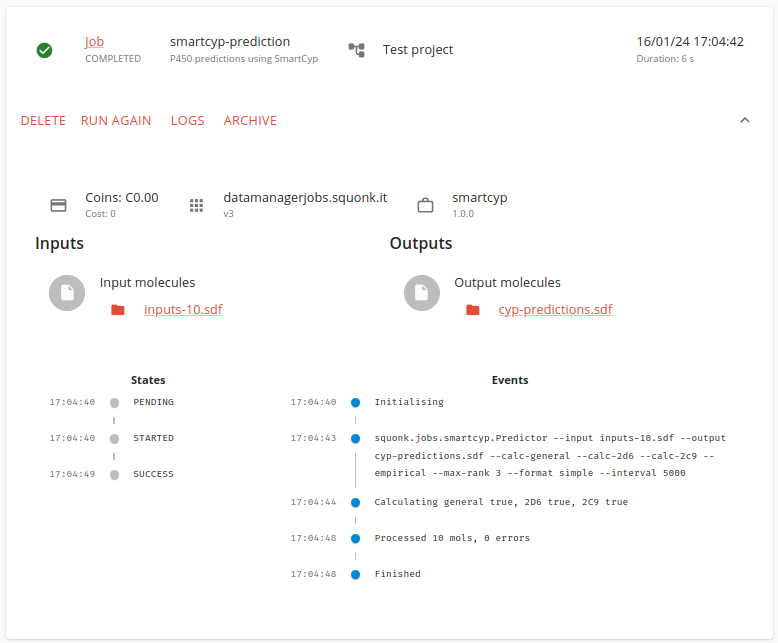
And you might wonder how these jobs are created. We have a mechanism for defining a new job and adding it to a Squonk2 instance. We’ll probably blog about that in more detail later, but this GitHub repo has lots of examples and some basic documentation. Generally speaking it would take about half a day to add a new simple job to the system.
So far most jobs have been created at Informatics Matters, but we also have 3rd parties who have created new ones too.
You can access Squonk here. You can register for an account.
latest posts
by year
2024
2023
2021
2020
Fragment Network REST API Cookie-cutting Ansible Kubernetes Projects Deploying container images from a private GitLab registry Fragment network basics Fragment network intro Redirecting to www with an nginx ingress Installing Kubernetes with Pharos Virtual screening for SARS-Cov-2 main protease inhibitors
2019
2018
by category
Blog
Containers
Software design
Automation
AWS ParallelCluster v3 Custom Images Migrating to AWS ParallelCluster v3 Kubernetes object linting with popeye GitHub Actions for container images Cookie-cutting Ansible Kubernetes Projects Installing Kubernetes with Pharos Building machine images with Packer Python and the Jenkins API Applying the build process to the deployment
IaC
Docking
Fragment network
Kubernetes
Kubernetes PreStop Lifecycle Hooks A kubernetes volume replicator Fixing a broken etcd cluster Kubernetes object linting with popeye Cookie-cutting Ansible Kubernetes Projects Deploying container images from a private GitLab registry Redirecting to www with an nginx ingress Installing Kubernetes with Pharos
Web
Ansible
Python
Squonk